
//

//

//

Pebbles and exposed aggregate concrete (less maintenance than pebbles)

Gallery of Chronotope Wall House / UnSangDong Architects - 8

Carolina by Alessio Albi
What is CQRS?
CQRS is an architectural pattern, where the acronym stands for Command Query Responsibility Segregation. We can talk about CQRS when the data read operations are separated from the data write operations, and they happen on a different interface.
In most of the CQRS systems, read and write operations use different data models, sometimes even different data stores. This kind of segregation makes it easier to scale, read and write operations and to control security - but adds extra complexity to your system.
Node.js at Scale is a collection of articles focusing on the needs of companies with bigger Node.js installations and advanced Node developers. Chapters:
The level of segregation can vary in CQRS systems:
In the simplest data store separation, we can use read-only replicas to achieve segregation.
In a typical data management system, all CRUD (Create Read Update Delete) operations are executed on the same interface of the entities in a single data storage. Like creating, updating, querying and deleting table rows in an SQL database via the same model.
CQRS really shines compared to the traditional approach (using a single model) when you build complex data models to validate and fulfil your business logic when data manipulation happens. Read operations compared to update and write operations can be very different or much simpler - like accessing a subset of your data only.
In our Node.js Monitoring Tool, we use CQRS to segregate saving and representing the data. For example, when you see a distributed tracing visualization on our UI, the data behind it arrived in smaller chunks from our customers application agents to our public collector API.
In the collector API, we only do a thin validation and send the data to a messaging queue for processing. On the other end of the queue, workers are consuming messages and resolving all the necessary dependencies via other services. These workers are also saving the transformed data to the database.
If any issue happens, we send back the message with exponential backoff and max limit to our messaging queue. Compared to this complex data writing flow, on the representation side of the flow, we only query a read-replica database and visualize the result to our customers.
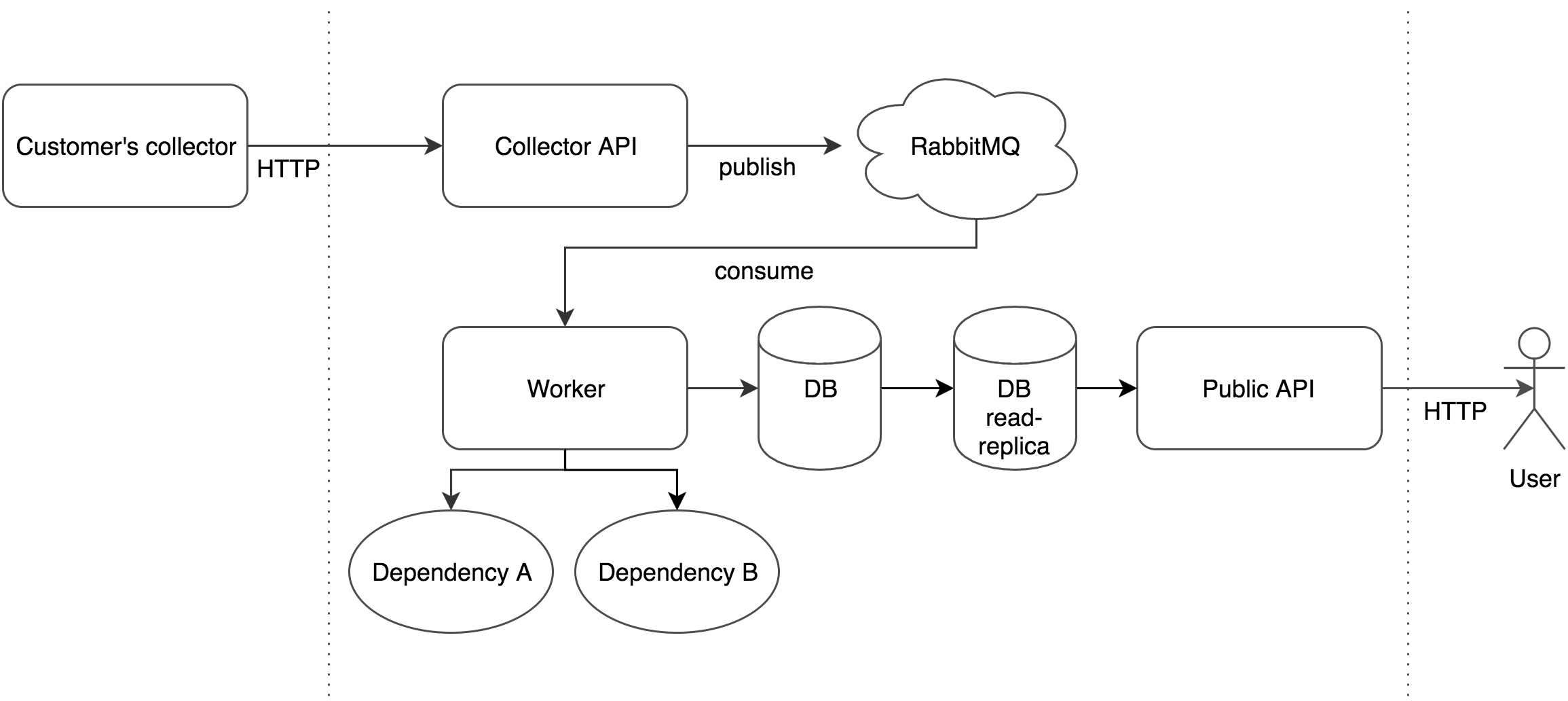 Trace by RisingStack data processing with CQRS
Trace by RisingStack data processing with CQRS
I've seen many times that people are confusing these two concepts. Both of them are heavily used in event driven infrastructures like in an event driven microservices, but they mean very different things.
To read more about Event Sourcing with Examples, check out our previous Node.js at Scale article.
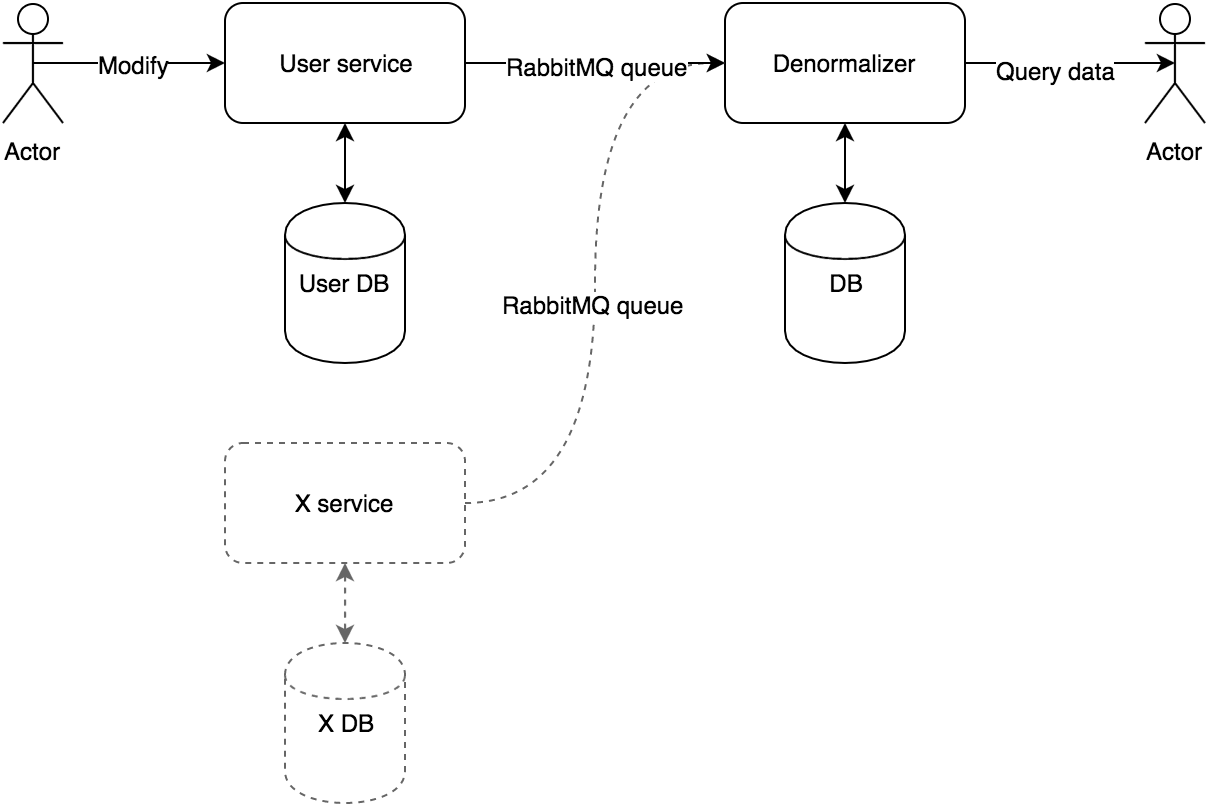
In some event driven systems, CQRS is implemented in a way that the system contains one or multiple Reporting databases.
A Reporting database is an entirely different read-only storage that models and persists the data in the best format for representing it. It's okay to store it in a denormalized format to optimize it for the client needs. In some cases, the reporting database contains only derived data, even from multiple data sources.
In a microservices architecture, we call a service the Denormalizer if it listens for some events and maintains a Reporting Database based on these. The client is reading the denormalized service's reporting database.
An example can be that the user profile service emits a user.edit event with { id: 1, name: 'John Doe', state: 'churn' } payload, the Denormalizer service listens to it but only stores the { name: 'John Doe' } in its Reporting Database, because the client is not interested in the internal state churn of the user.
It can be hard to keep a Reporting Database in sync. Usually, we can only aim to eventual consistency.
For our CQRS with Denormalizer Node.js example visit our cqrs-example GitHub repository.
CQRS is a powerful architectural pattern to segregate read and write operations and their interfaces, but it also adds extra complexity to your system. In most of the cases, you shouldn't use CQRS for the whole system, only for specific parts where the complexity and scalability make it necessary.
To read more about CQRS and Reporting databases, I recommend to check out these resources:
I’m happy to answer your CQRS related questions in the comments section!
What is CQRS?
CQRS is an architectural pattern, where the acronym stands for Command Query Responsibility Segregation. We can talk about CQRS when the data read operations are separated from the data write operations, and they happen on a different interface.
In most of the CQRS systems, read and write operations use different data models, sometimes even different data stores. This kind of segregation makes it easier to scale, read and write operations and to control security - but adds extra complexity to your system.
Node.js at Scale is a collection of articles focusing on the needs of companies with bigger Node.js installations and advanced Node developers. Chapters:
The level of segregation can vary in CQRS systems:
In the simplest data store separation, we can use read-only replicas to achieve segregation.
In a typical data management system, all CRUD (Create Read Update Delete) operations are executed on the same interface of the entities in a single data storage. Like creating, updating, querying and deleting table rows in an SQL database via the same model.
CQRS really shines compared to the traditional approach (using a single model) when you build complex data models to validate and fulfil your business logic when data manipulation happens. Read operations compared to update and write operations can be very different or much simpler - like accessing a subset of your data only.
In our Node.js Monitoring Tool, we use CQRS to segregate saving and representing the data. For example, when you see a distributed tracing visualization on our UI, the data behind it arrived in smaller chunks from our customers application agents to our public collector API.
In the collector API, we only do a thin validation and send the data to a messaging queue for processing. On the other end of the queue, workers are consuming messages and resolving all the necessary dependencies via other services. These workers are also saving the transformed data to the database.
If any issue happens, we send back the message with exponential backoff and max limit to our messaging queue. Compared to this complex data writing flow, on the representation side of the flow, we only query a read-replica database and visualize the result to our customers.
Trace by RisingStack data processing with CQRS
I've seen many times that people are confusing these two concepts. Both of them are heavily used in event driven infrastructures like in an event driven microservices, but they mean very different things.
To read more about Event Sourcing with Examples, check out our previous Node.js at Scale article.
In some event driven systems, CQRS is implemented in a way that the system contains one or multiple Reporting databases.
A Reporting database is an entirely different read-only storage that models and persists the data in the best format for representing it. It's okay to store it in a denormalized format to optimize it for the client needs. In some cases, the reporting database contains only derived data, even from multiple data sources.
In a microservices architecture, we call a service the Denormalizer if it listens for some events and maintains a Reporting Database based on these. The client is reading the denormalized service's reporting database.
An example can be that the user profile service emits a user.edit event with { id: 1, name: 'John Doe', state: 'churn' } payload, the Denormalizer service listens to it but only stores the { name: 'John Doe' } in its Reporting Database, because the client is not interested in the internal state churn of the user.
It can be hard to keep a Reporting Database in sync. Usually, we can only aim to eventual consistency.
For our CQRS with Denormalizer Node.js example visit our cqrs-example GitHub repository.
CQRS is a powerful architectural pattern to segregate read and write operations and their interfaces, but it also adds extra complexity to your system. In most of the cases, you shouldn't use CQRS for the whole system, only for specific parts where the complexity and scalability make it necessary.
To read more about CQRS and Reporting databases, I recommend to check out these resources:
I’m happy to answer your CQRS related questions in the comments section!

//